Real MysQL 8.0 1권을 읽고 정리한 내용입니다.
잘못된 내용이 있을 경우 댓글로 남겨주시면 감사하겠습니다🙏
InnoDB 스토리지 엔진 아키텍처
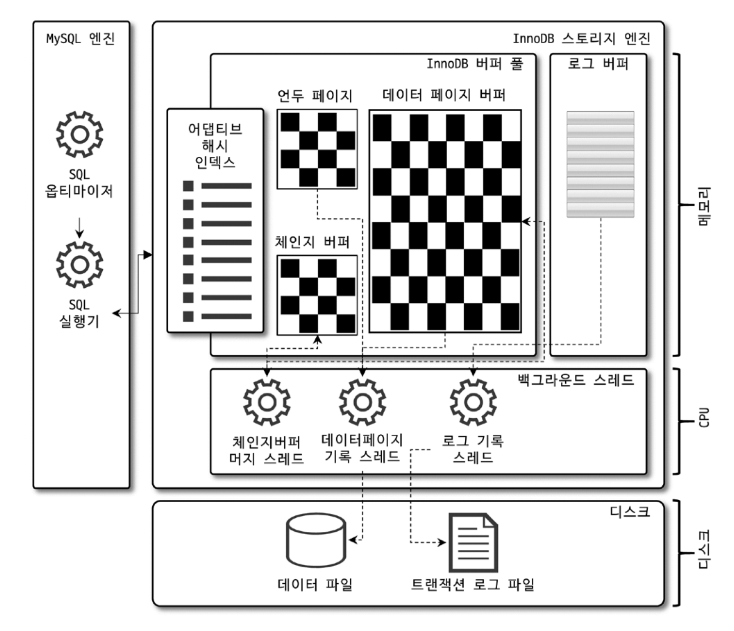
MySQL 의 스토리지 엔진 중 가장 많이 사용되는 InnoDB 스토리지 엔진은 위와 같은 구조로 되어있습니다.
InnoDB 는 MySQL 에서 사용할 수 있는 스토리지 엔진 중에서 거의 유일하게 record lock 을 제공합니다.
그래서 높은 동시성 처리가 가능하고, 성능이 뛰어납니다.
프라이머리 키에 의한 클러스터링
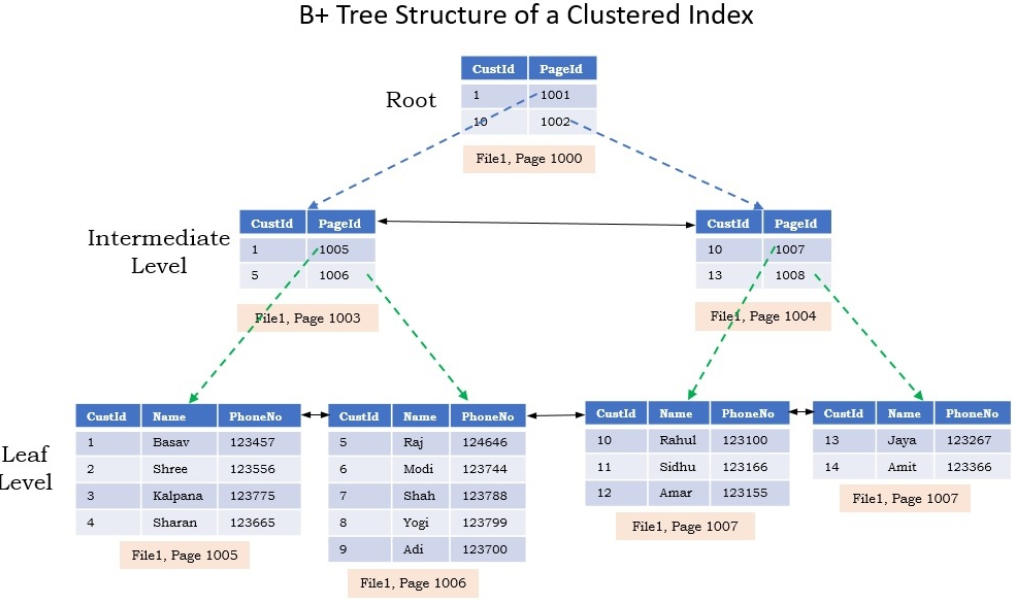
InnoDB 의 모든 테이블은 프라이머리 키(PK)를 기준으로 클러스터링 되어 저장됩니다.
즉, 테이블의 레코드들은 디스크에 PK 의 순서대로 저장된다는 뜻 입니다.
그리고 세컨더리 인덱스*는 레코드의 주소 대신, PK 값을 논리적인 주소로 사용합니다.
PK 를 기준으로 모든 레코드들이 클러스터링 되어 저장되어있기 때문에, PK 를 이용한 범위 탐색은 아주 빠르게 처리됩니다.
그래서 옵티마이저가 실행계획을 결정하며 인덱스를 선택할때, PK 는 다른 인덱스보다 선택될 확률이 높습니다.
이러한 구조를 Oracle DB 에서는 IOT(Index organized table) 라는 이름으로 제공한다고 합니다.
참고 : IOT(INDEX ORGANIZED TABLE) 란?
세컨더리 인덱스(보조 인덱스)*
기본 인덱스(Primary Index) 가 아닌 인덱스
왜래키 지원
왜래키에 대한 지원은 InnoDB 스토리지 엔진에서 제공하는 기능으로, MyISAM 이나 Memory 테이블에서는 사용할 수 없습니다.
DB 서버 운용상의 불편함 때문에 왜래키를 사용하지 않는 경우가 있다고 하는데, 그 이유는 다음과 같습니다.
- 부모, 자식 테이블 모두
인덱스를 생성해야함 - 변경시
제약조건을 만족하는지 확인하는 작업이 발생- 이 작업을 위해 부모, 자식 테이블 모두에
잠금(Lock)이 발생 - 이로 인하여 데드락이 발생할 수 있음
- 이 작업을 위해 부모, 자식 테이블 모두에
급하게 작업해야할 때, 제약조건 을 만족하는 순서로 DB 작업을 하는건 아주 어렵습니다.
그래서 제약조건 확인 작업을 일시중지할 수 있다고 합니다.
SET foreign_key_checks=OFF;
-- 필요한 작업 수행
SET foreign_key_checks=ON;위 처럼 시스템 설정을 변경하면 외래키 확인 작업을 하지 않기 때문에, 빠르게 처리할 수 있다고 합니다.
하지만, 왜래키 확인을 해제했다고, 관계가 깨진 상태의 데이터를 유지해도 되는건 아닙니다.
그래서 반드시 부모 테이블 레코드를 삭제했다면, 관련된 자식 테이블의 레코드도 삭제하여 일관성을 맞춘 상태로 다시 활성화 해야합니다.
MVCC(Multi Version Concurrency Control)
MVCC 는 레코드 레벨의 트랜잭션을 지원하는 DBMS 들이 지원하는 기능입니다.
MVCC 의 가장 큰 목적은 잠금(Lock)을 사용하지 않는 일관된 읽기(Consistent Read)를 제공하는데 있습니다.
이를 위해서 하나의 레코드에 대한 여러 버전을 제공한다고 하는데요.
아래에서 예시를 통해 알아보겠습니다.
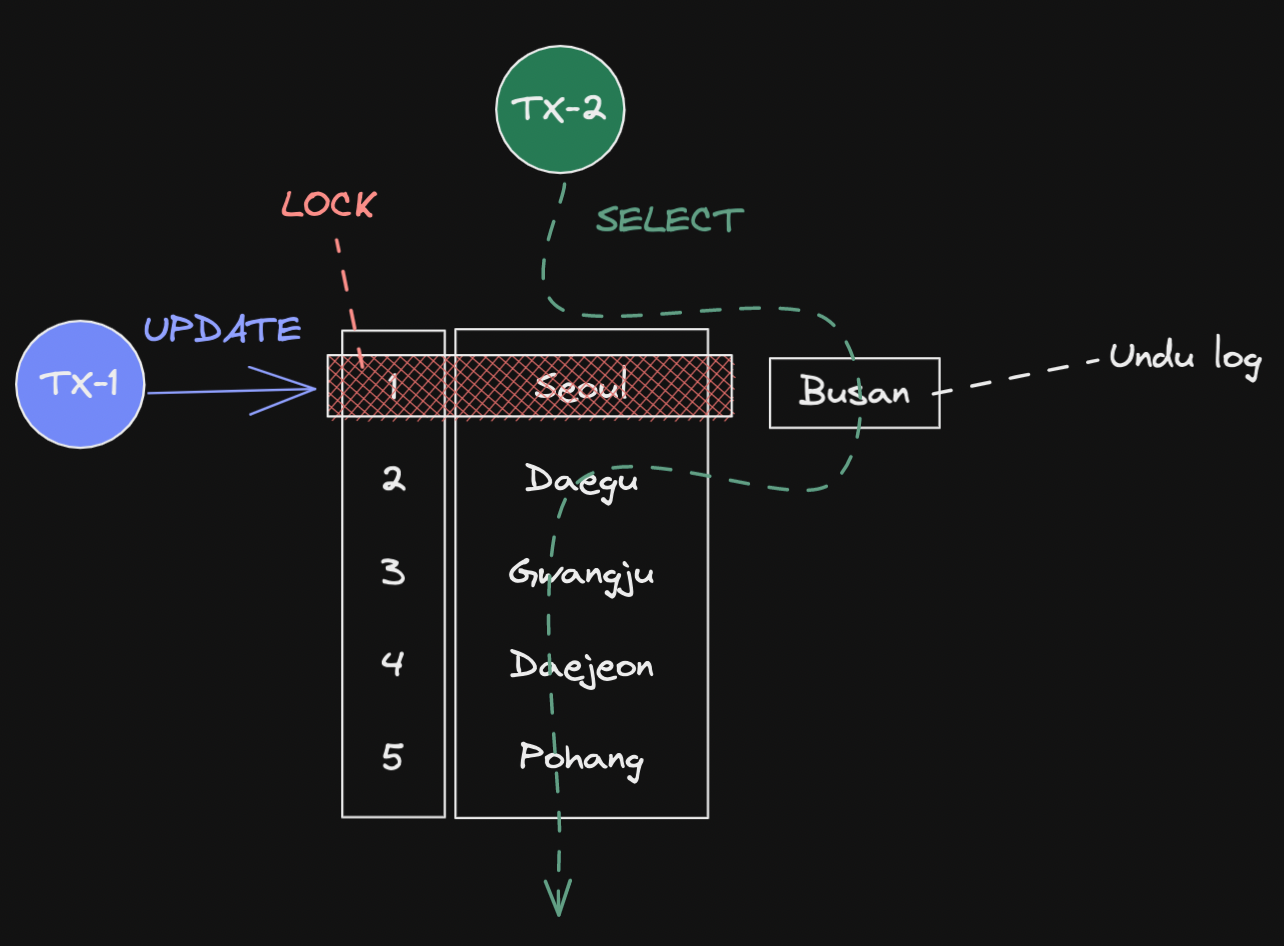
INSERT INTO member (id, name, city) VALUES (1, 'Jay', 'Busan');위 INSERT 쿼리가 실행되면, 데이터베이스는 아래와 같은 상태가 됩니다.
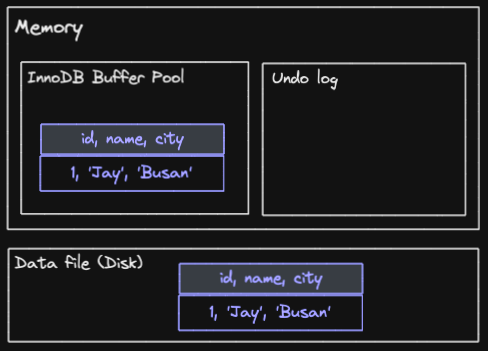
Member 테이블에 추가한 데이터는 디스크의 Data file 에도 저장되고, 메모리의 InnoDB Buffer pool 에도 저장됩니다.
이후 조회시에는 디스크 I/O 는 발생하지 않고, InnoDB Buffer pool 에서 조회하게 됩니다.
UPDATE member SET city='Seoul' WHERE id=1;city 를 변경하는 UPDATE 쿼리가 실행되었습니다.
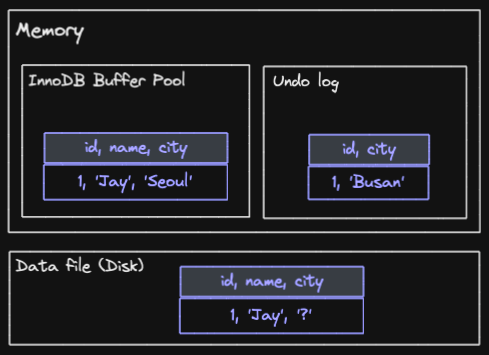
그러면 InnoDB Buffer pool 에는 COMMIT 여부와 상관없이, Seoul 로 업데이트 됩니다.
그리고 Undo log 에는 변경 이전의 데이터인 Busan 이 기록됩니다.
이제 SELECT 쿼리를 실행하면, 해당 세션의 격리 수준(Transaction Isolation Level) 에 따라 다른 결과가 나오게 됩니다.
격리 수준 에 대한 자세한 설명이 필요하시다면 이 포스팅을 참고해주시기 바랍니다.Read Uncommitted 인 경우에는 COMMIT 되지 않은 데이터도 읽기 때문에 InnoDB Buffer Pool 에 있는 데이터를 읽습니다.
하지만 나머지의 경우에는 COMMIT 된 데이터를 읽기 때문에, Undo log 에서 읽는다는 차이점이 있습니다.
잠금 없는 일관된 읽기(Non-Locking Consistent Read)
InnoDB 스토리지 엔진에서는 MVCC 를 이용해서, 잠금(Lock)없이 읽기 작업을 수행할 수 있습니다.
그래서 다른 트랜잭션이 특정 record 를 Lock 해놓은 상태라도, 기다리지않고 읽기 작업이 가능합니다.
격리 수준의 중에서 SERIALIZABLE 을 제외한 다른 수준들에서는 순수한 SELECT 작업은 항상 Lock 에 영향을 받지 않고 바로 실행됩니다.
자동 데드락 감지
InnoDB 스토리지 엔진은 내부적으로 교착상태를 감지하기 위해서 잠금 대기 목록을 그래프(Wait-for List) 형태로 관리합니다.
그리고 데드락 감지 스레드가 주기적으로 잠금 대기 목록을 확인하여 교착상태에 빠진 트랜잭션 중 하나를 강제 종료합니다.
이때 Undo log 의 양이 많은 트랜잭션이 강제 종료 대상이 되며, 상대적으로 Undo log 가 적은 트랜잭션은 Rollback 됩니다.
자동화된 장애 복구
InnoDB 스토리지 엔진에는 장애로부터 데이터를 보호하기 위한 여러가지 매커니즘이 탑재되어 있습니다.
그래서 MySQL 서버가 시작될 때 완료되지 못한 트랜잭션이나, 디스크에 일부만 기록된 데이터 페이지 등에 대한 복구 작업이 진행됩니다.
InnoDB 는 다음과 같은 복구 옵션을 제공합니다
- 1(SRV_FORCE_IGNORE_CORRUPT) : 손상된 데이터가 발견되도 무시하고 MySQL 서버를 시작함
- 2(SRV_FORCE_NO_BACKGROUND) : 백그라운드 메인 스레드를 시작하지 않고 MySQL 서버를 시작함
- 3(SRV_FORCE_NO_TRX_UNDO) : MySQL 서버가 시작할때 이전에 완료되지 않은 트랜잭션을 복구하는 작업을 동작하지 않게함
- 4(SRV_FORCE_NO_IBUF_MERGE) : Insert Buffer 내용을 무시하고 MySQL 서버를 시작함
- 5(SRV_FORCE_NO_UNDO_LOG_SCAN) : Undo log 를 무시하고 MySQL 서버를 시작함
- 6(SRV_FORCE_NO_LOG_REDO) : Redo log 를 무시하고 MySQL 서버를 시작함
InnoDB 버퍼 풀(InnoDB Buffer Pool)
버퍼 풀(InnoDB Buffer Pool)은 디스크의 데이터 파일이나 인덱스 정보를 메모리에 캐시해 두는 공간으로 사용됩니다.
또한 버퍼 풀은 쓰기 지연을 위한 버퍼로도 사용됩니다.
버퍼 풀의 크기 설정
MySQL 5.7 부터 버퍼 풀의 크기를 동적으로 조절할 수 있게 되었습니다.
처음으로 MySQL 서버를 세팅한다면 다음과 같은 방법으로 버퍼 풀 크기 설정을 찾아가는 방법을 권장합니다.
- 운영체제 메모리 공간 확인
- 전체 메모리 공간이 8G 미만
50% 정도만 InnoDB 버퍼 풀 크기로 설정하고, 조금씩 올리면서 최적점을 찾기 - 전체 메모리 공간이 50G 이상
20~35G 정도를 InnoDB 버퍼 풀 크기로 설정
- 전체 메모리 공간이 8G 미만
버퍼 풀의 구조
버퍼 풀은 디스크에서 읽은 데이터 페이지를 공간을 페이지 단위로 쪼개어 저장합니다.
그리고 이 페이지들을 관리하기 위해 LRU 리스트, 플러시 리스트, 프리 리스트 를 관리합니다.
LRU(Least Recently Used) 리스트
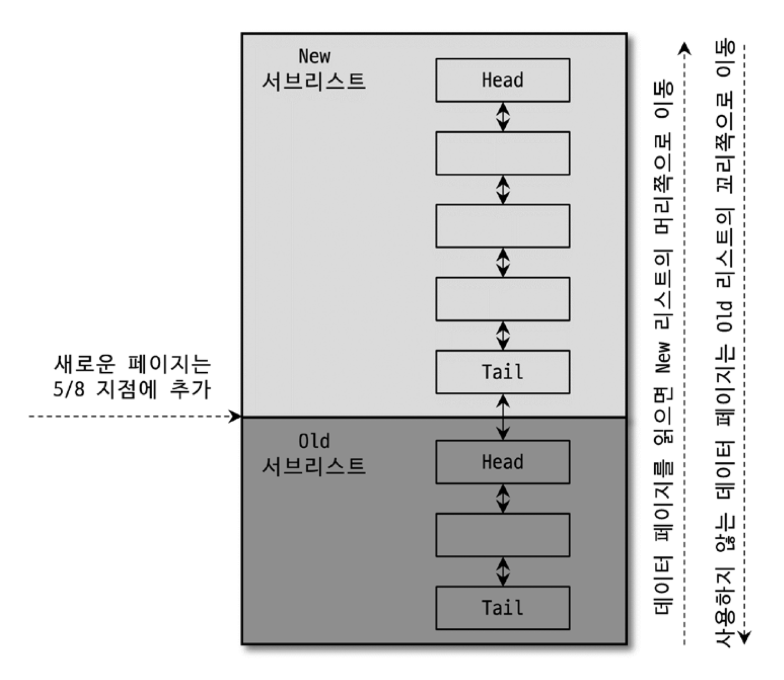
LRU 리스트는 New 서브리스트 와 Old 서브리스트 로 나누어집니다.
여기서 New 서브리스트 는 MRU(Most Recently used) 리스트이고, Old 서브리스트 가 LRU 리스트 입니다.
버퍼 풀에서 자주 사용되는 페이지는 상위(New 서브리스트)로 이동되고, 자주 쓰이지 않는 데이터는 하위(Old 서브리스트)로 이동됩니다.
플러시(Flush) 리스트
플러시 리스트는 디스크로 동기화 되지 않은 데이터를 가진 페이지의 변경 시점 기준의 페이지 목록을 관리합니다.
즉, 지연 쓰기로 인해 UPDATE 쿼리 실행하여 발생한 변경사항이 즉시 디스크에 반영되지 않기 때문에 이를 관리하기 위함입니다.
프리(Free) 리스트
버퍼 풀에서 데이터로 채워지지 않은, 비어있는 페이지들의 목록입니다.
버퍼풀과 리두 로그
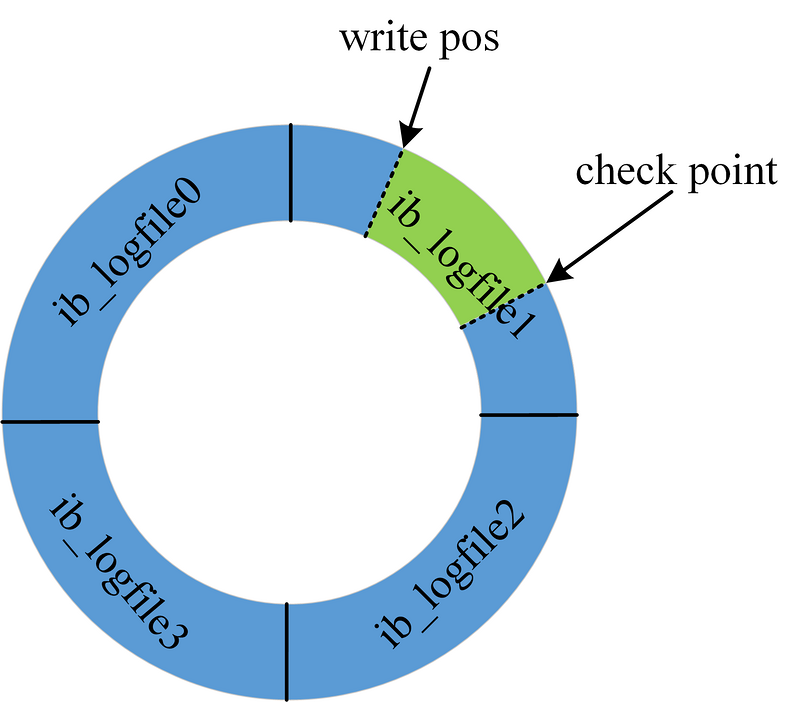
버퍼 풀에는 변경사항이 아직 디스크로 반영되지 않은 더티 페이지(Dirty Page)를 가지고 있습니다.
언젠가 디스크로 반영이 되어야 하기 때문에 Redo log 를 이용하여 버퍼 풀에 무한정 머무르지 않도록 관리합니다.
Redo log 는 위 그림처럼 복수의 로그파일을 원형으로 구성하여 사용됩니다.
그리고 반영되어야 하는 내용들이 차곡 차곡 쌓이게 됩니다.
그러다가 write pos 와 check point 가 만나게 되면 다른 작업을 멈추고, 디스크에 해당 내용들을 동기화 합니다.
버퍼 풀 플러시(Buffer Pool Flush)
MySQL 5.6 까지는 더티 페이지를 Disk 로 Flush 하는 기능이 안정적이지 않아, 갑자기 디스크 I/O 가 폭증하는 경우가 있었습니다.
그러나 MySQL 5.7 버전과 8.0 버전이 되며 Flush 기능이 안정화 되었습니다.
InnoDB 는 더티 페이지들을 다음과 같은 2개의 Flush 기능을 백그라운드로 실행하여 디스크에 동기화 합니다.
- 플러시 리스트(Flush list) 플러시 : 버퍼 풀의 플러시 리스트를 디스크로 동기화 합니다.
- LRU 리스트(LRU list) 플러시 : 사용 빈도가 낮은 데이터 페이지들을 디스크로 동기화 하고 풀에서 제거합니다.
Double Write Buffer
버퍼 풀의 더티 페이지를 디스크로 동기화 하는 과정에서 일부만 기록되는 문제가 발생하면, 그 페이지의 내용을 복구하기 어렵습니다.
이를 파셜 페이지(Partial-page) 또는 톤 페이지(Torn-page) 라고 하는데, 하드웨어의 오작동이나 MySQL 의 비정상 종료로 발생할 수 있습니다.
그래서 InnoDB 는 이런 문제를 방지하기 위해 Double-Write 기법을 이용합니다.
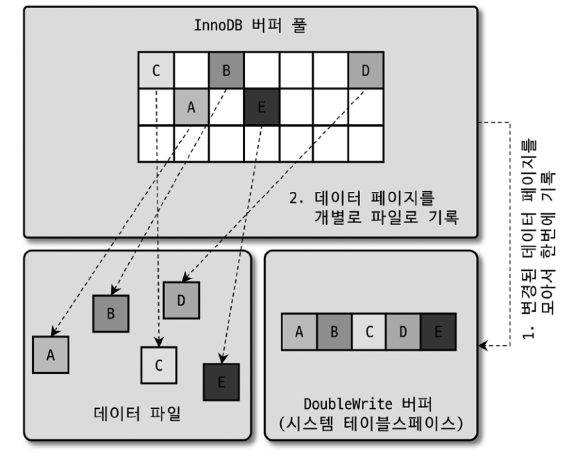
각 페이지는 디스크에 랜덤하게 위치해있기 때문에, 변경 작업을 하기 위해서는 각 페이지의 위치를 찾아가야 합니다.
A~E 중에서 C 까지 썼다가 디스크 오류로 D,E 가 디스크에 반영되지 않으면 문제가 발생합니다.
그래서 디스크에 위치한 DoubleWrite 버퍼에 한번의 디스크 I/O 로 연속적으로 해당 내용들을 저장합니다.
그리고 나서 실제 위치에 각 페이지들을 저장하게 됩니다.
언두 로그
InnoDB 스토리지 엔진은 트랜잭션과 격리 수준을 보장하기 위해 변경 이전의 데이터를 백업합니다.
이렇게 백업된 데이터는 Undo log 라고도 하고, MVCC 를 위해 사용되기도 합니다.
Undo log 가 제공하는 기능을 조금 더 살펴보면 다음과 같습니다.
- 트랜잭션 보장 : 트랜잭션 롤백이 발생하면, 변경 이전의 데이터로 돌리기 위한 데이터를 제공
- 격리 수준 보장 : 트랜잭션 격리 수준에 따라 변경 중인 데이터 대신, 이전 데이터를 제공하는 역할
체인지 버퍼(Change Buffer)
record 가 INSERT, UPDATE 될때 데이터 파일 뿐만 아니라, 인덱스도 변경해야 합니다.
그러나 인덱스는 디스크에 랜덤하게 저장되어있기 때문에 인덱스가 많다면 상당히 많은 시간이 소요됩니다.
그래서 InnoDB 는 변경할 인덱스가 버퍼 풀에 있다면 바로 변경하고, 아니라면 임시 공간에 저장해두고 결과를 사용자에게 반환합니다.
이 공간을 체인지 버퍼 라고 합니다.