4. R-Tree 인덱스
MySQL 에는 공간 인덱스(Spatial Index) 라는 개념이 있습니다.
2차원의 데이터를 인덱싱하고, 검색하는 목적의 인덱스 입니다.
기본적인 내부 메커니즘은 B-Tree 와 흡사하지만, B-Tree 는 1차원의 스칼라 값* 차이점은 2차원 공간 개념 값을 저장한다는 것입니다.
스칼라 값
크기, 양만을 나타내는, 숫자로만 표시되는 값을 의미합니다.
예) 우유 1팩의 용량, 비행기의 무게 등
MySQL 은 공간 데이터를 다룰 수 있는 공간 확장(Spatial Extention)을 제공하는데 다음과 같은 기능들이 있습니다.
- 공간 데이터를 저장할 수 있는
데이터 타입 - 공간 데이터 검색을 위한
공간 인덱스(R-Tree 알고리즘) - 공간 데이터의
연산 함수(거리 또는 포함 관계의 처리)
더 자세한 내용은 아래에서 알아보겠습니다.
4-1 구조 및 특성
MySQL 은 공간 정보의 저장 및 검색을 위해 여러가지 도형(Geometry) 정보를 저장할 수 있는 데이터 타입을 제공합니다.
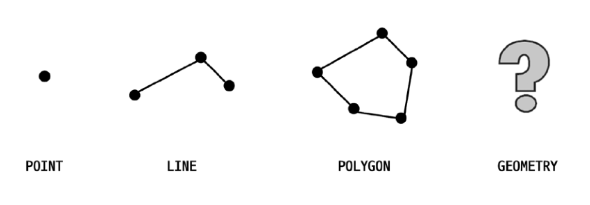
위 그림은 MySQL 에서 저장할 수 있는 도형의 종류와 이에 대응하는 데이터 타입 입니다.
여기서 마지막의 Geometry 타입은 나머지 3개의 타입을 모두 저장할 수 있는 데이터 타입 입니다.
MBR(Minumum Bounding Rectangle)
공간 정보 검색을 위해서 MBR 이라는 개념을 함께 알아야 하는데요.
MBR 이란, 도형을 감싸는 가장 작은 크기의 사각형 입니다.
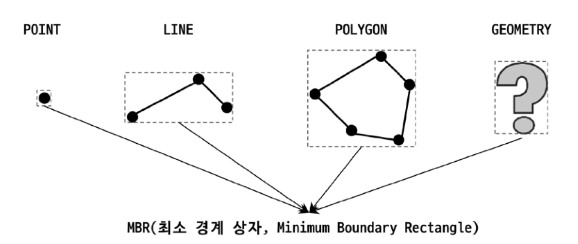
위 그림에서 각 도형들을 감싸는 가장 작은 크기의 사각형(MBR)들 보실 수 있습니다.
위는 공간 데이터의 예시 입니다.
이 도형들을 MBR 이 어떻게 되는지 간단한 예시를 통해 알아보겠습니다.
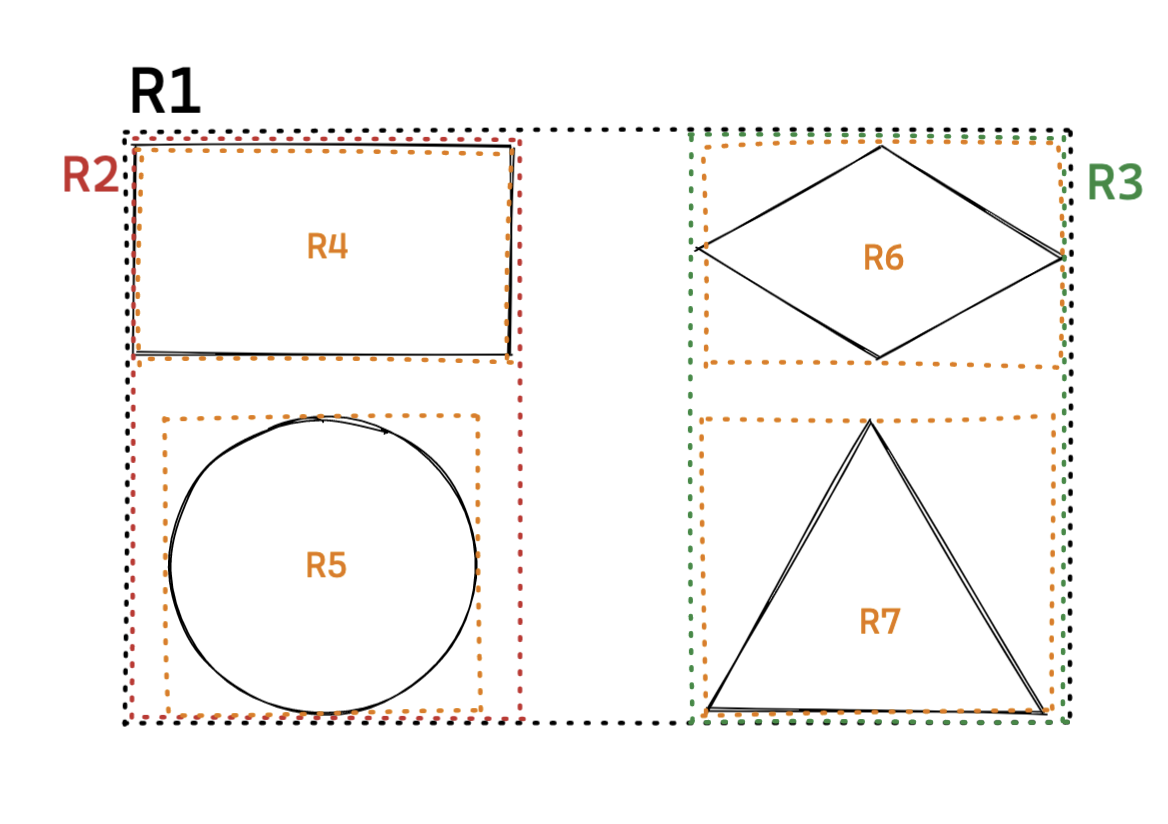
최상위 레벨 : R1
차상위 레벨 : R2, R3
최하위 레벨 : R4~R7
위 그림 기준으로 최상위 레벨 에 해당하는 사각형은 R-Tree 의 루트 노드에 저장되는 데이터 입니다.
그리고 차상위 레벨 은 브랜치 노드에 저장되고, 최하위 레벨 은 리프 노드 에 저장됩니다.
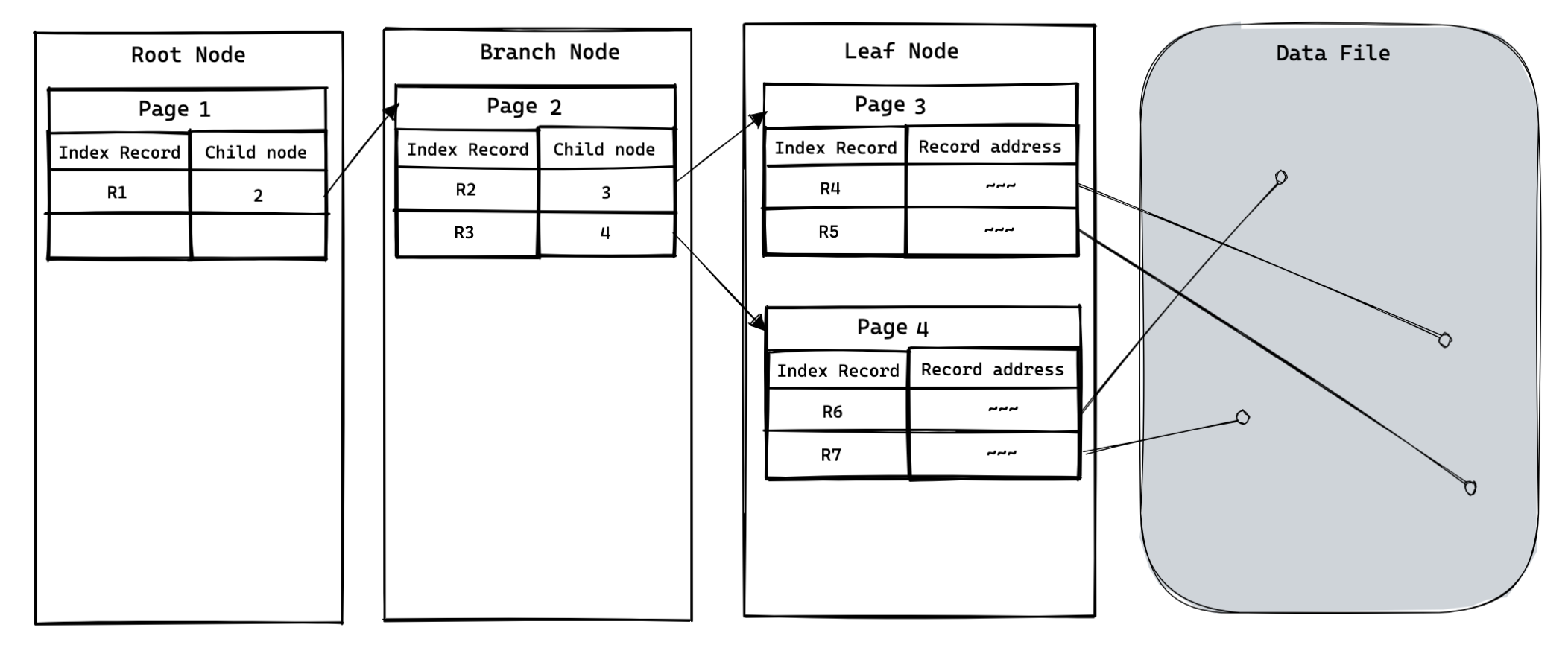
그래서 R-Tree 의 구조는 다음과 같이 각 MBR 들을 저장하게 됩니다.
4.2 R-Tree 인덱스의 용도
R-Tree 는 보통 WGS84(GPS) 기준의 위도, 경도 좌표 저장에 주로 사용됩니다.
그러나 CAD/CAM 혹은 회로 디자인 처럼 좌표 기반 정보를 다루는 경우에도 모두 적용 가능합니다.
그러나 R-Tree 는 ST_Contains(), ST_Within() 등과 같은 포함 관계를 비교하는 함수로 검색을 수행하는 경우에만 사용됩니다.
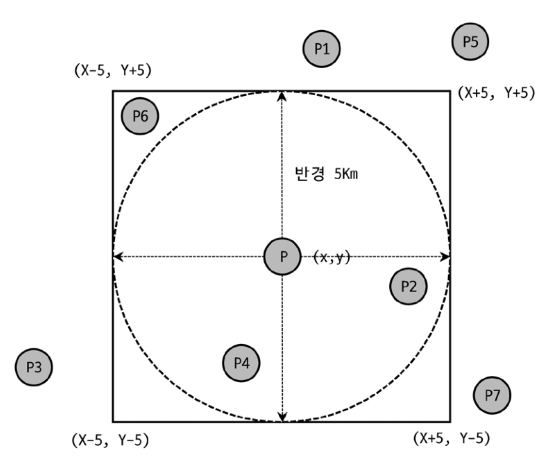
대표적으로는 현재 위치 반경 5km 이내의 음식점을 찾는 경우에 사용할 수 있습니다.
ST_Distance(), ST_Distance_Sphere() 과 같은 함수도 있지만 효율성이 떨어지기 때문에, 위에서 언급한 두 함수를 사용하는것을 권장합니다.
> SELECT * FROM locations
WHERE ST_Contains(range, point)
> SELECT * FROM locations
WHERE ST_Within(point, range)하지만 ST_Contains(), ST_Within() 검색은 사각형을 기준으로 검색하기 때문에,
P6 처럼 5km 원 안에는 포함되지 않지만, 사각형 안에 위치하는 경우도 포함됩니다.
반드시 원 안에 포함되는 경우만 필요하다면 다음과 같이 조건을 추가해야합니다.
> SELECT * FROM locations
WHERE ST_Contains(range, point)
AND ST_Distance(center, point) <= 5 * 1000 /* 5km */4.3 실습
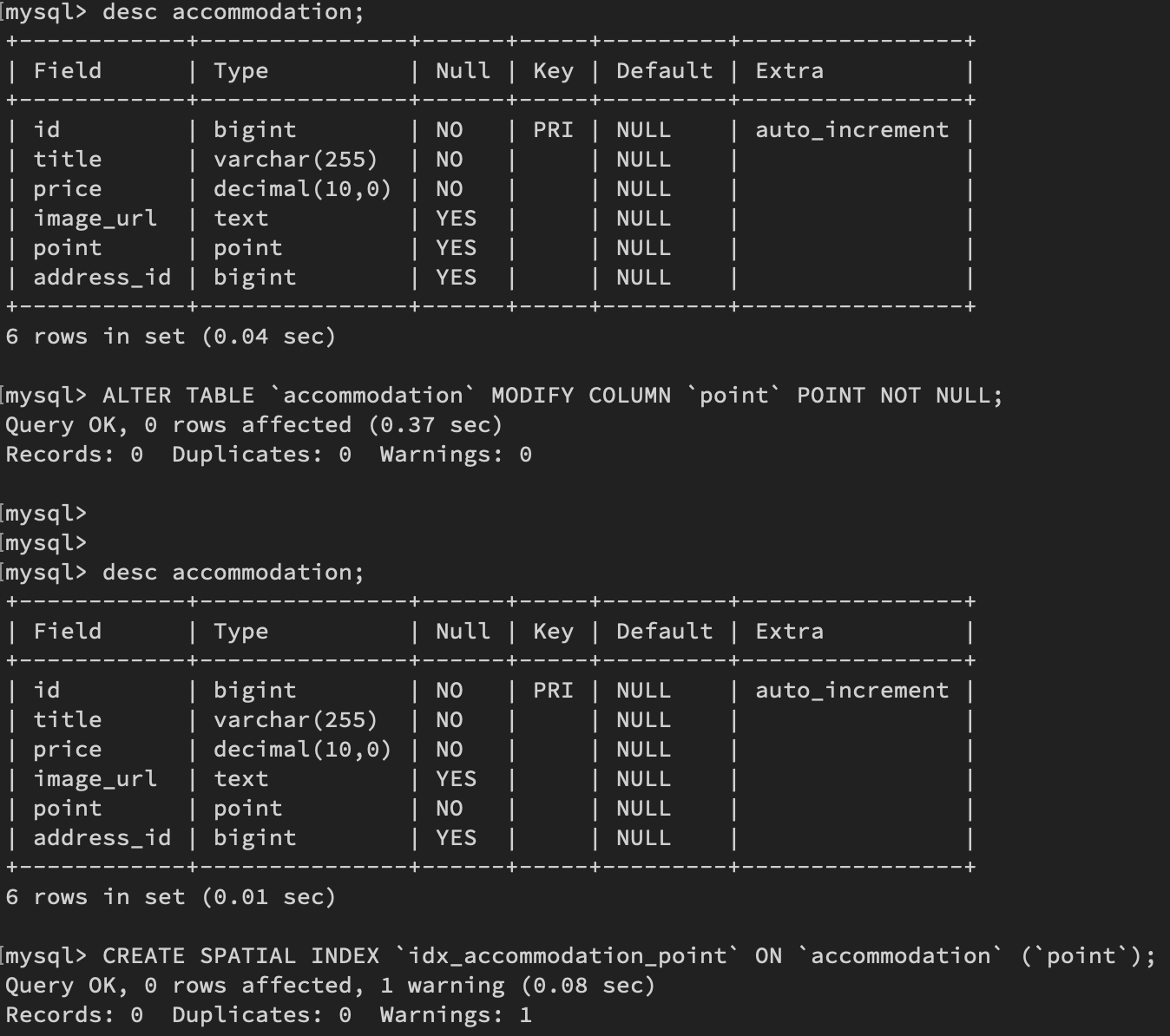
프로젝트를 하며, 숙소 데이터에 숙소 위치를 저장하는 point 라는 컬럼이 있습니다.
(데이터 타입과 겹치는 이름을 지정해버려서, 변경할 예정..😅)
이 컬럼의 데이터 타입은 POINT 타입인데, Index 를 부여하려면 NOT NULL 이 되어야 합니다.
4.3.1 숙소 위치 컬럼 NOT NULL 로 변경
> ALTER TABLE `테이블` MODIFY COLUMN `컬럼` 데이터타입 제약조건;
> ALTER TABLE `accommodation` MODIFY COLUMN `point` POINT NOT NULL;만약, 해당 컬럼이 NULL 로 들어가있는 레코드가 있다면, NOT NULL 로 변경할 수 없습니다.
4.3.2 숙소 위치 컬럼에 SPATIAL INDEX 추가
> CREATE SPATIAL INDEX `인덱스명` ON `테이블` (`컬럼`);
> CREATE SPATIAL INDEX `idx_accommodation_point` ON `accommodation` (`point`);4.3.3 위치 검색 실습
- 기준 위치 : 코드스쿼드
longitude(y) : 37.490790latitude(x) : 127.033374
SELECT * FROM accommodation
WHERE ST_Distance_Sphere(POINT(127.033374, 37.490790), point) <= 5 * 1000;ST_Distance_Sphere() 함수는 POINT 를 srid-4326 으로 변환하여 거리를 계산할 수 있게 해줍니다.
> SELECT Point(127.033374, 37.490790);
+------------------------------------------------------+
| Point(127.033374, 37.490790) |
+------------------------------------------------------+
| 0x00000000010100000059A2B3CC22C25F40179AEB34D2BE4240 |
+------------------------------------------------------+
> SELECT ST_SRID(Point(127.033374, 37.490790), 4326);
+------------------------------------------------------+
| ST_SRID(Point(127.033374, 37.490790), 4326) |
+------------------------------------------------------+
| 0xE6100000010100000059A2B3CC22C25F40179AEB34D2BE4240 |
+------------------------------------------------------+변경된 결과로 봐서는 이진 데이터의 헤더만 변경하는것으로 보입니다.
POINT : 0x00000000000010100000059A2B3CC22C25F40179AEB34D2BE4240
POINT : 0xE6100000000010100000059A2B3CC22C25F40179AEB34D2BE4240
SELECT * FROM accommodation
WHERE ST_Contains(POINT(127.033374, 37.490790), point) <= 5 * 1000;SELECT id
, title
, ST_LATITUDE(ST_SRID(point, 4326)) as latitude
, ST_LONGITUDE(ST_SRID(point, 4326)) as longitude
, ST_DISTANCE_SPHERE(POINT(127.033374, 37.490790), point) as distance
FROM accommodation
WHERE ST_Distance_Sphere(POINT(127.033374, 37.490790), point) <= 2 * 1000
ORDER BY distance DESC;5. 전문 검색 인덱스
지금까지 살펴본 인덱스들은 크지 않고 키워드한 작은 값에 대한 인덱스 입니다.
MySQL 의 B-Tree 가 그 예인데요.
실제 컬럼의 크기가 1mb 라도, 1000byte(MyISAM) 또는 3072byte(InnoDB) 까지 잘라서 인덱스로 사용합니다.
전문 검색 인덱스는 특정 키워드가 포함된 문서를 검색하는 전문(Full Text) 검색에 사용됩니다.
5.1 인덱스 알고리즘
전문 검색에서 본문에서 사용자가 검색할 키워드를 분석하여, 빠른 검색용으로 사용될 수 있도록 키워드로 인덱스를 구축합니다.
이런 분석 기법에는 어근 분석 과 n-gram 분석 알고리즘 으로 구분할 수 있습니다.
5.1.1 어근 분석 알고리즘
전문 검색 인덱스는 다음의 두 가지 중요한 과정을 거쳐서 색인 작업이 수행됩니다.
- 불용어(Stop Word) 처리
- 어근 분석(Stemming)
불용어 처리는 가치 없는 단어를 필터링하여 제거하는 작업입니다.
불용어는 개수가 많지 않아 MySQL 서버 코드에 상수로 정의되어 있지만, 사용자가 별도로 불용어를 정의하는 기능도 제공합니다.
어근 분석은 검색어로 선정된 단어의 뿌리(원형)을 찾는 작업입니다.
영어는 시제나 단수 복수에 따라 단어가 변환되기 때문에 어근 분석이 중요하지만,
한글, 일본어 등은 이보다 문장의 형태소를 구분하여 명사와 조사를 구분하는것이 중요합니다.
CREATE SPATIAL INDEX `idx_accommodation_point` ON `accommodation` (`point`);