
본 포스팅은 강대명님이 발표하신,
goorm 4회 인프라, 어디까지 구축해 봤어?를 듣고 정리한 내용 입니다
1. 어떤 인프라 구성이 좋은 구성일까?
일단, 가장 중요한 것은 회사와 서비스의 규모 에 맞는 구성이다.
그래도 꼭 몇가지를 요소를 생각해 보면 다음과 같다
- 장애에 강건한 구조
- 확장이 쉽다
- 관측(모니터링)이 쉽다
- 비용이 적게 든다
- (인프라를 효율적으로 사용하고 있다?)
1.1 소규모 서비스(스타트업 등)
만약 On-prem 인프라를 구성한다면?
- 장비가 몇년 뒤에 들어올 수 있음을 잘 알아야 함
- 반도체 대란으로 제때 수급이 힘듦
- 충분한 여유분의 HW 를 보유해야함
- 좋은 SE(Server Engineer)인력이 있어야 함
- 이런 분들은 보통 큰 회사에 많음..(작은 규모 회사에서 채용하기 쉽지 않음)
- 새벽에도 문제가 발생하면 IDC 에 달려갈 사람이 있어야 함
On-prem 으로 인프라를 구성하면 위와 같은 많은 요소들을 고려해야 하는데 스타트업이 이 비용을 감당하기 힘들 수 있다.
게다가, 스타트업은 MVP 로 빠르게 치고나가야 하는데 On-prem 인프라가 발목을 잡을 수 있다.
그래서 스타트업은 대부분의 경우에는 클라우드 가 매우 유리하다.
1) 소규모 서비스 예시
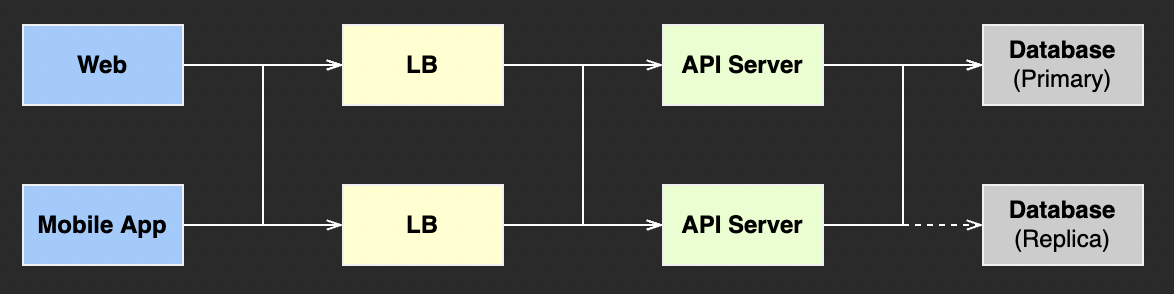
2) 모니터링
클라우드인 경우라면, 다음과 같은 툴들을 사용한다.
- CloudWatch
- Sentry
보통 CloudWatch 로 에러 로그를 보내고, Log Insights 로 단위시간내 가장 많이 발생한 장애를 확인한다.
(강대명님의 발표 자료 예시에는 2시간으로 끊어서, 그 기간내 가장 많이 발생한 에러를 확인할 수 있도록 되어있었음!)
3) 고가용성(High Availability)
고가용성을 위해서 일반적으로 여러대의 서버를 두고 이를 기반으로 구성한다.
그러면 만약 실제 100개의 Request 를 처리할 수 있다면, 2대의 서버만 있으면 충분할까?
아니다, 더 여유를 두고 인프라를 구성해야 한다.
(특히, 클라우드는 HW 스위칭이 아니기 때문에 반응속도가 느려서 더 여유를 둬야 한다.)
더 여유를 두고 인프라를 구성해야 한다는 말씀은 AWS ECS 환경에서 Memory 100% 사용으로 인한 장애 경험이 떠올라서 더욱 공감되었다.
그리고 만약 On-prem 인프라를 구성하고 있다면 다음과 같은 사항을 고려해야 한다
- Peak 타임을 버틸 수 있는 것보다 더 많은 HW 를 사전에 보유하고 있어야 한다
- 서버가 몇대 죽어도 버틸 수 있어야 한다.
- 장비 증설 계획을 미리 계획하고 증설해야 한다.
- 사용량 모니터링 필수
- 장비 증설에 몇달 걸릴 수 있음
- 클라우드든 On-prem 이든 쉽게 장비를 추가할 수 있게 서비스를 설계해야 한다.
4) Data Replication
서비스에서 가장 중요한 것은 데이터 이기 때문에, 보통 복제(Replica)를 둔다.
그래서 DB 장애 발생 시, Replica 를 이용하여 빠르게 복구할 수 있는 구조를 만들어 둔다.
주DB 를 Master, 복제를 Slave 라고 할때, 장애 발생 시 시나리오는 다음과 같다.
MasterDB 에 장애 발생 인지- 서비스가
Slave를 바라보도록 변경(이 시점에서 이제 이 DB 가Master가 된다) - 장애가 발생한 DB 복구 작업 후, Replication 을 다시 활성화 한다.
이렇게 2중화를 하여 서비스에는 크게 영향이 가지 않도록 구성한다.
5) IaC(Infrastructure as Code)
IaC 란, 인프라를 코드로 관리한다는 매커니즘이다.
IaC 도구로 Terraform 을 주로 사용하는데, 이 도구는 클라우드 기반이다.
IaC 로 인프라를 관리한다면 아주 많은 장점이 있다.
- 변경 이력 추적
- Rollback 이 쉬움
- 담당자 부재/변경 시에도 대응할 수 있음
- 불변 인프라(Immutable Infrastructure)
- 영원히 바뀌지 않는다는 것이 아니라, 해당 버전의 코드로 인프라를 프로비저닝 하면 항상 같은 결과가 나온다는 의미
(개인적으로는 Immutable 이라는 단어보다,멱등성이라는 단어가 더 적절하지 않을까 싶다.)
- 영원히 바뀌지 않는다는 것이 아니라, 해당 버전의 코드로 인프라를 프로비저닝 하면 항상 같은 결과가 나온다는 의미
- 변경 사항에 대한 리뷰(검토)가 쉬움
- Github Pull Request 에 Atlantis 를 붙이면 더 편하게 리뷰/적용할 수 있음!
IaC 는 모든 인프라 설정이 코드로 관리되고, 이게 그대로 클라우드에 프로비저닝 되는 구조이다.
코드 변경내역을 통해 인프라의 변경 구조 이력을 추적할 수 있는 장점이 있는데,
그래서 변경한 인프라 구조에서 문제가 발생한다면 이전 버전으로 Rollback 하기도 쉽다.
그리고 만약 담당자가 바뀌더라도, 인프라 구조를 파악하고 관리하는데 훨씬 수월하다.
수동 → IaC 로 마이그레이션
달리는 기차의 바퀴를 바꾸는 일이기 때문에, 사실 쉽지는 않다.
그래서 전면적으로 바꾸는것은 거의 불가능하고, 부분적으로 조금씩 바꿔가는 방식이 더 낫다.
1-2 대규모 서비스
대규모 서비스의 경우 자체적으로 IDC 를 구성하기도 하고, 클라우드로 구성하기도 한다.
1) 대규모 서비스의 종류
대규모 서비스 인프라를 구성할 때 크게 두 가지로 나눠서 생각해볼 수 있다.
트래픽이 예측 되는 경우
트래픽이 예측되는 경우는 보통 계획된 트래픽 증가일 것이다.
- 이벤트 : 카카오톡 • 라인 등의 새해 이벤트,
- 특별한 날 : Black Friday, Cyber Monday, 광군절 등
트래픽이 예측되지 않는 경우
이런 경우는 또 크게 Auto-scaling 이 감당할 수 있는지 여부로 나눠서 생각해볼 수 있다.
- Auto-scaling 이 감당 가능한 경우
- 평소와 Peak 시간대의 트래픽이 많이 차이나지 않는 경우
- Auto-scaling 이 감당하기 힘든 경우
- 평소와 Peak 시간대의 트래픽이 차이가 몇 백배 이상인 경우
- Auto-scaling 으로도 in-minute traffic 이 기하급수적으로 늘어나는 경우는 감당할 수 없다.
(Auto-scaling 이 트래픽 증가를 못따라간다)
그래서 수요를 최대한 예측하여 미리 서버를 늘려놓는 방법 밖에는 없다.
(강대명님이 AWS 와 얘기 해봤는데, 그쪽에서도 미리 늘려놓는 방법밖에 없다 했다고 한다..!)
2) 간단한 대규모 서비스 예시
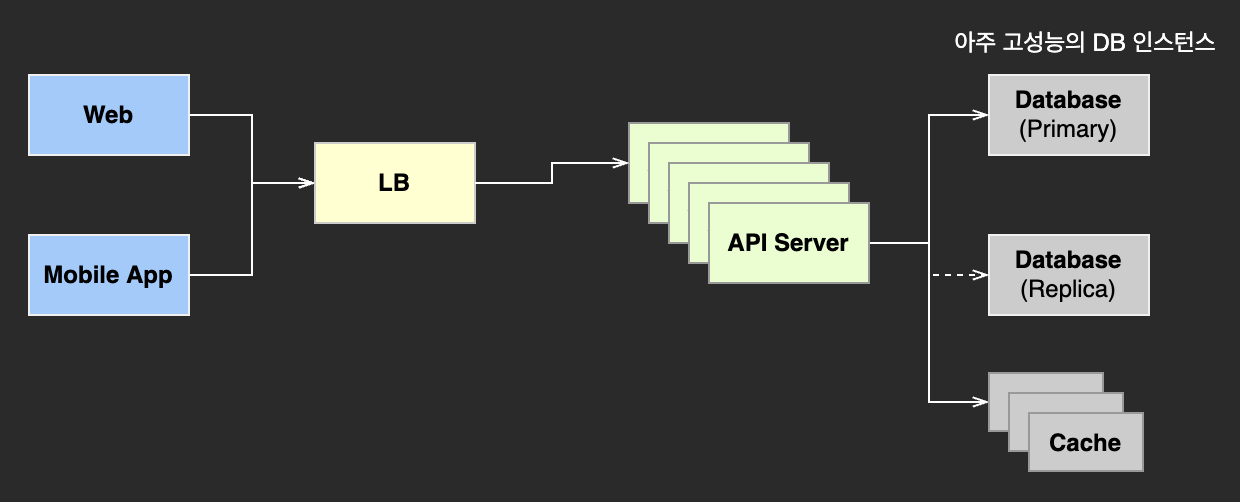
이 예시는 API 서버의 경우에는 Scale-in/out 되도록 설계되어있고, DB 는 Scale-up 하여 구성되어있다.
3) 데이터 이슈
대규모 서비스의 경우에는 모든 장애 발생 가능성에 대해 대비해야 한다.
하지만, 대부분의 이슈는 데이터 이슈 인 경우가 많다.
위의 간단한 대규모 서비스 예시를 보면, 아주 고성능의 DB 를 사용한다.
하지만 결국 하나의 인스턴스로 처리할 수 있는 양에는 한계가 있다.
그리고 모든 정보가 저장된 이 DB 에 장애가 발생한다면, 모든 데이터에 접근이 불가능하다는 치명적인 단점이 있다.
그래서 데이터를 분리 할 필요가 있다.
4) 샤딩(Sharding)
샤딩은 DB 파티셔닝이랑 비슷한 개념이다.
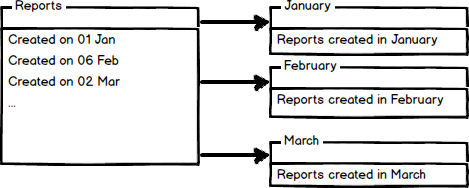
파티셔닝은 수평 파티셔닝(Horizontal partitioning), 수직 파티셔닝(Vertical partitioning) 두 종류로 나눌 수 있다.
- 수평 분할 예(Row 단위로 나눔)
-
- 수직 분할 예(Column 단위로 나눔)
-
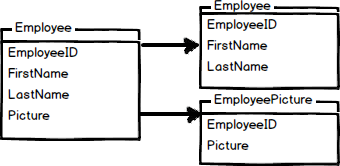
이 처럼 대규모 서비스에서는 DB 서버를 샤딩하여 관리하는 경우가 많다.
그러면 대규모 서비스에서는 DB 는 수평 분할, 수직 분할 중 어떤것을 선택해야할까?
사실 둘다 적절히 고려하는게 좋지만, 샤딩은 수평 분할(Horizontal Partitioning)을 의미한다.
수평 분할을 하더라도 그 기준과 잘 정하는것이 중요한데, 일반적으로 PK 를 기준으로 정렬하는 경우가 많다.
그리고 그 기준을 어떻게 활용하느냐에 따라 대표적으로 다음과 같은 경우를 예로 들 수 있다.
- Range Sharding : 기준 key 의 범위를 지정해서 각 shard 에 분산 저장
- Modular Sharding : 기준 Key 를 모듈러 연산한 결과대로 해당되는 shard 에 저장(예를 들면
짝수 • 홀수,key % shard 개수등)
그래서 Sharding 을 할 때는 이들의 차이와 장단점을 이해하고, 우리 서비스와 더 잘 맞는 규칙을 선택해야 한다.
(특히, Shard Redistribution, 데이터 몰림 현상 을 잘 고려해야 한다.)
추가로 읽어보면 좋은 글들
Range Sharding
(이번 세미나에서는 여러 Sharding 종류 중 Range Sharding 에 대해 설명해주셨습니다.)
- 장점
- 추가하기 쉽다
- 단점
- 서비스 부하의 불균형(데이터 몰림 현상)
Range Sharding 은 추가하기 쉽고 직관적이라는 장점이 있습니다.
하지만, 단점으로는 데이터 몰림 현상으로 인한 부하 불균형을 초래할 수 있습니다.
예를 들면, 서비스의 초기 고객의 경우 충성 고객인 경우가 많다.
그런데 이벤트를 하여 다수의 고객들이 들어오게 되는 경우가 있는데, 이들은 소수만 남고 나머지는 떠나는 경우가 많다.
그러면 이 시기에 들어온 고객들이 많이 저장된 shard 는 상대적으로 부하를 덜 받게 될것이고,
나머지 shard 에 상대적으로 부하가 몰리는 현상이 생길 것이다.
그래서 이런 경우를 극복하기 위한 다음과 같은 방법이 있다.
- 특정 서버의 로드가 낮다면, 특정 Range 구간의 신규 유저를 해당 shard 로 저장한다.
(단, 이런 경우 규칙 관리를 정말 잘해야 한다)
5) 샤딩의 단점
- Join 연산을 할 수 없다
- => 그래서 Application 레벨에서 Join 하여 구현해야 한다.
그럼 스타트업(소규모 서비스)도 샤딩을 고려해야 할까?
사실 이 주제에 대해서는 여러 의견이 많지만, 미래를 위해 잘 선택해야 한다.
당장 DB 를 샤딩하지는 않겠지만, 어플리케이션 코드는 조금 더 생각해봐야 한다.
지금은 하나의 DB 인스턴스를 사용하니 어플리케이션 코드에 Join 연산을 한 기능을 붙일 수 있겠지만,
만약 서비스가 너무 잘되어 DB 를 샤딩하게 된다면... 미래의 나는 과거의 나를 원망할것이다.
그래서 샤딩을 위해서는 FK 만 저장하고 어플리케이션 레벨에서 조합하는 방식을 쓰는게 좋은데,
대신 이렇게하면 개발 시간이 더 많이 걸릴 수 있으니 장단점을 잘 생각하여 선택해야 한다.
6) 대규모 서비스 예시
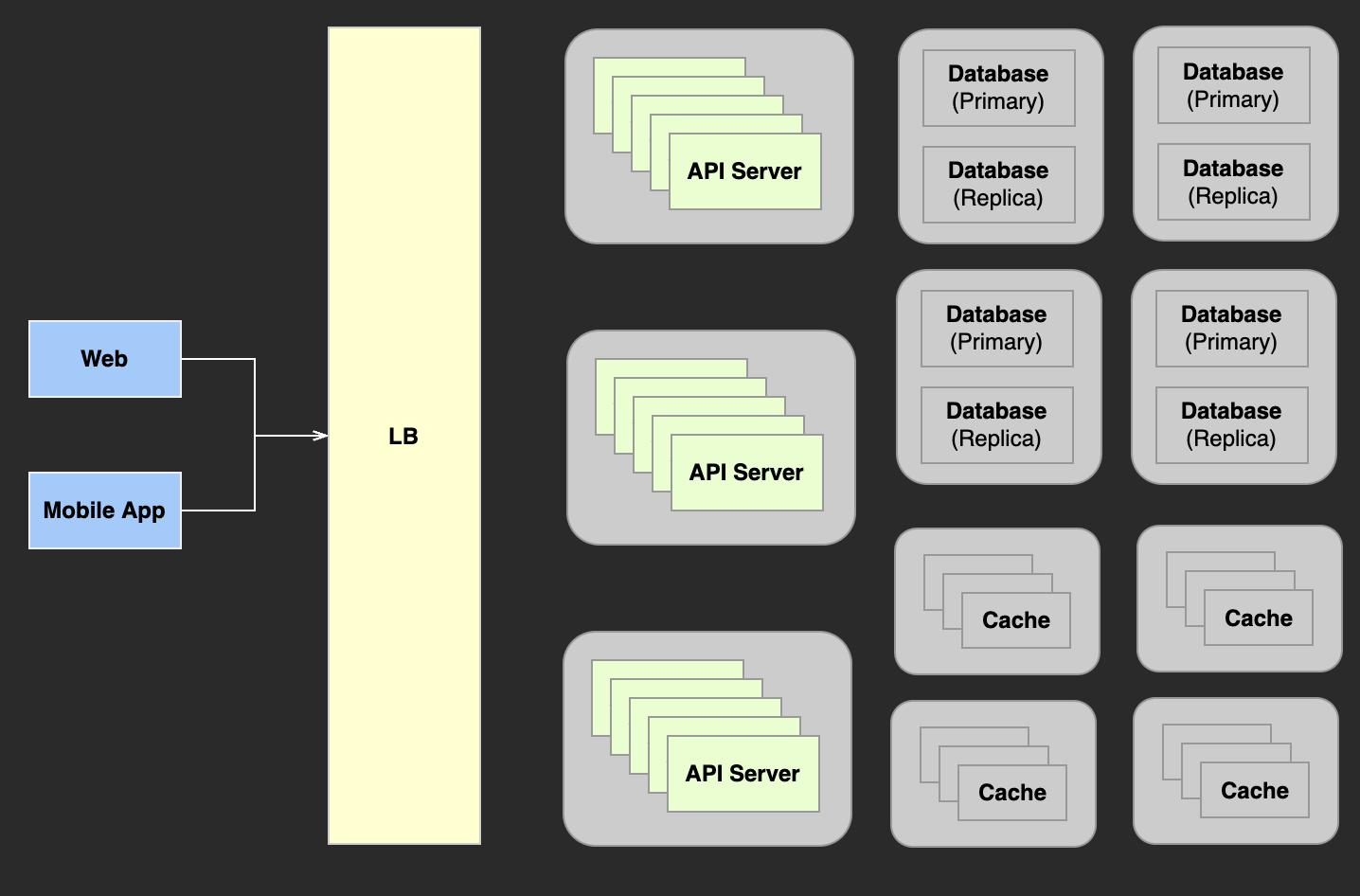
서비스간 장애 영향도를 낮추기 위해 Circuit Breaker 패턴을 이용하기도 한다.
그리고 대규모 서비스에서는 캐시조차 샤딩을 한다.
사례(K 모 서비스)
- DAU : 8M
- MAU : 15M
- Daily API call count : 420M
위와 같은 트래픽을 지탱하는 서비스를 아래와 같은 인프라가 지탱하고 있었다.
(2014~2015년도 당시 사례)
- Cache
- Redis 274대 (5.2 TB)
- Memcached 137대 (3.3 TB)
2. 핵심 정리
- 데이터의 샤딩 규칙
- 왠만하면 Range Sharding 하는게 좋다
- 코드를 Range Sharding 할 수 있는 구조로 (미리)만들어 놓자
(SQL Join 을 최소한으로 사용하자)
- 인프라 네이밍
- AWS Seoul Region 만 쓰다가, 해외 사업을 진행한다면?
같은 이름의 서버가 필요하다면?- 서버의 이름만 보고도 어떤 일을 하는지 알 수 있도록 정하기
- VPC 의 CIDR 규칙
- 서비스간에 겹치지 않도록 잘 분리해서 정하는게 좋다
- 하지만, 잘 정해놔도 나중에 인수/합병되는 일이 생길 경우 충돌이 날 수 있다
- AWS Seoul Region 만 쓰다가, 해외 사업을 진행한다면?
3. On-prem -> Cloud 마이그레이션
- Cloud 는 HW 와 같은 사양이라고 같은 성능을 내진 않는다.
- 같은 사양을 쓸 수 없을수도 있다(더 높은 단계의 인스턴스를 써야할수도 있음)
- Redis 의 경우에는 CPU(Hz)의 영향을 받는데, Cloud 로 이전하면서 CPU 차이로 처리량이 떨어질 수 있다
- 같은 소프트웨어가 아닐 수 있다.
- Hadoop 이나 Spark 는 AWS 의 EMR 과 조금 다를 수 있다
- 작동하던 쿼리가 작동하지 않을 수 있음
- 예로, Hadoop, Spark 의
Distribute라는 키워드가 EMR 에서 지원하지 않은 경우도 있었다
(지금은 해결 되었는지 모르겠음)
- Hadoop 이나 Spark 는 AWS 의 EMR 과 조금 다를 수 있다
- Lesson Learned
- 사고방식의 전환이 필요
- 필요하면 만들고, 필요없어지면 지우기
- 클라우드는 On-prem 에 비해 유연하다는 장점이 있다
4. QnA
클라우드 전환의 핵심은?
비용(물적, 시간적, 인적 비용 모두 포함)
- On-prem 서버의 증설/제거/관리 비용과 클라우드 사용 비용을 비교하여 생각하기
- 클라우드는 모든 Action 이 API 로 제공되기 때문에, 규칙 부여, 자동화가 가능하다는 것이 큰 장점
Python(Django)로 대규모 서비스 가능?
언어마다 차이는 있겠지만 어떤 언어도 가능하다.
오히려 데이터를 잘 설계하는게 중요하다.
데이터를 잘 설계하면, 앞단(서비스의 구현)은 유연하게 변경 가능하다.
엑티브 센터 구축 시 DB 위치, 세션 서버 위치 동기화 방법이 궁금합니다
(...코멘트를 해주셨는데 내용이 어려워 잘 기록하지 못했음 ㅠㅠ)
아키텍처 설계 시 참고한 사이트?
Google 기술 블로그, Netflix 기술블로그, 네이버 기술블로그 및 컨퍼런스 자료들
Range Sharding -> Modular Sharding 변경 시 어려운 점?
샤딩 변경이 불가능한 건 아닌데, 잘 일어나진 않음(아주 어렵고 까다로운 작업이라...)
그리고 Range Sharding -> Modular Sharding 으로 변경하는 경우는 흔치 않은 것 같음
(이런 경우는 거의 없다는 말씀인 것 같다)
샤딩 후 가장 중요한 것은 데이터 정합성 검증인데, 단기간에 검증하기는 쉽지 않다.
그래서 old, new 를 호출하는 API 두개를 만들고 응답은 old 의 결과를 사용하고 new 와 비교하는 방식으로 일정 기간을 두고 검증하기도 한다.
Serverless -> 대규모 인프라로의 이전이 어려운가?
규모가 작다면 Serverless 도 괜찮다고 생각한다.
하지만, Serverless 는 메모리와 타임아웃 제한이 있어서 한계가 존재할 수 있다.
이를 대응하고 관리할 여유가 있거나, 인력이 있다면 가능??
Trade-off 를 잘 생각하자
5. 세미나를 듣고..
이번 세미나에서 배운 내용 중 핵심 키워드를 선택해보자면 성능 향상, 샤딩 을 선택하겠습니다.
서비스가 성장함에 따라 많은 데이터가 쌓이고 트래픽이 늘어나며 점점 요청 처리 오버헤드가 늘어납니다.
이 때문에 발생한 서비스 품질 저하를 해결하기 위해 이런 접근 방법들이 나온 것 같습니다.
성능 향상을 위해 많은 요청을 처리할 수 있도록 어플리케이션 서버를 늘리고, DB 인스턴스를 스케일업 합니다.
하지만 이렇게 하더라도 DB 인스턴스가 하나이니 성능 향상 한계에 부딛히게 됩니다.
그래서 결국 DB 인스턴스도 수평 확장을 하여 분산 처리를 할 수 있는 아키텍처가 도입됩니다.
즉, 모든건 서비스 품질 향상(성능 향상)이 주 목적인데, 이를 더 좁게 본다면 조회 성능 향상이라고도 볼 수도 있습니다.
서비스 종류에 따라 다르겠지만, 대부분의 경우 요청 중 거의 대부분은 조회 요청이기 때문입니다.
이전에 지인을 통해 대규모 서비스 개발자로 재직중인분의 얘기를 건너들었던 적이 있었습니다.
현업에서 Join 아예 쓰지 않고, 테이블도 비정규화해서 엄청나게 많은 컬럼들을 테이블에 넣어서 사용한다는 것이었는데요.
(모든 회사가 이렇다는 얘기는 아닙니다)
개인적으로는 충격이었습니다..
그 테이블과 연결되는 엔티티도 지저분해지고, 도메인 로직도 지저분해지는것 아닌가 생각했습니다.
세미나를 듣기 전까지는 그렇게 해야하는 이유를 도저히 이해할 수 없었는데, 이제는 조금 납득이 됩니다.
먼저 그 정도 서비스라면 당연히 DB 는 샤딩되어있을 것이라는 생각이 들었습니다.
그래서 Join 을 쓰지않는게 아니라 쓸 수 없는거겠구나 싶었습니다.
그리고 비정규화된 테이블의 경우에는 아직 100% 납득이 가진 않지만, 조심스레 CQRS 의 영향이 아닐까 생각되었는데요.
명령 요청의 경우에는 정규화된 스키마에 저장하고, 조회용 스키마를 따로 두어 조회 요청 처리를 위해 사용하는게 아닐까 생각했습니다.
이번 세미나를 통해서 몰랐던 새로운 지식을 얻으며, 동시에 공부할 거리도 더 늘어난 것 같습니다.
어렴풋이나마 대규모 서비스 구성에 대해 살짝 맛본 것 같아 좋았습니다.