1. 디스크 읽기 방식
CPU나 메모리 처럼 전기적 특성을 띄 장치와 HDD, SDD 같은 기계식 장치는 처리속도 차이가 아주 많이 납니다.
그래서 쿼리의 성능을 좌우하는 것은, 어떻게 디스크 I/O 를 줄이느냐가 핵심이라고 합니다.
그러기 위해서는 먼저 디스크에 대해 살짝 짚고 넘어가야 합니다.
1-1. HDD 와 SSD
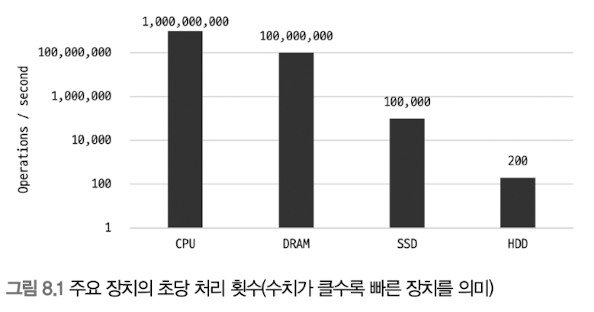
위는 컴퓨터 주요 장치들의 처리 속도 차트입니다.
기본적으로 CPU 의 처리속도는 SSD, HDD 에 비해 월등히 빠른 것을 보실 수 있습니다.
SSD 의 장점은 기존 HDD 보다 랜덤 I/O 가 훨씬 빠르다는 것 입니다.
그래서 DBMS 와 같이 순차 I/O 보다 랜덤 I/O 가 훨씬 더 자주 일어나는 환경에서는 SSD 가 적합합니다.
1-2. 랜덤 I/O 와 순차 I/O
데이터 페이지 3개를 디스크에 써야한다고 가정했을 때, 랜덤 I/O 와 순차 I/O 의 차이를 알아보겠습니다.
랜덤 I/O- 각 페이지가 다른위치에 있음
- 시스템 콜을 3번 호출
순차 I/O- 페이지들이 한 곳에 뭉쳐있음
- 시스템 콜을 1번 호출
이렇게 단순하게 계산하면 랜덤 I/O 는 순차 I/O 보다 약 3배 느리다고 할 수 있습니다.
DBMS 에서도 쿼리스의 성능이 떨어지는 원인은 결국, 랜덤 I/O 가 많이 발생해서라고 할 수 있는데요.
쿼리 튜닝은 결국 랜덤 I/O 를 줄여주는 것이고, 즉 모수(母數)를 줄이는 것이 핵심이라는 것입니다.
2. 인덱스란?
인덱스란 DBMS 가 원하는 데이터를 찾기 위해 사용하는 색인 이라고 할 수 있습니다.
데이터와 해당 데이터가 포함된 레코드의 키를 이용하여, key-value 로 저장해놓고 빠르게 찾아가는 방식입니다.
이렇게 원하는 데이터를 찾기 위해서는 정렬되어있어야 빠르게 찾을 수 있겠죠.
그래서 DBMS 에서는 칼럼의 값을 미리 정해진 순서로 정렬하여 보관합니다.
하지만 레코드를 저장할 때 부가적인 정보들을 함께 저장하고, 이를 정렬하는 오버헤드가 발생하는데요.
즉, 인덱스는 데이터의 저장 기능들(INSERT, UPDATE, DELETE)을 희생하여 조회(SELECT) 성능을 높이는데 사용된다고 할 수 있습니다.
3. B-Tree 인덱스
B-Tree(Balanced Tree) 는 DBMS 인덱싱 알고리즘 중 가장 많이 사용되는 알고리즘 입니다.
구조체 내에서 항상 정렬된 상태를 유지하여 빠르게 원하는 데이터에 도달할 수 있는 구조입니다.
3-1. 구조 및 특성
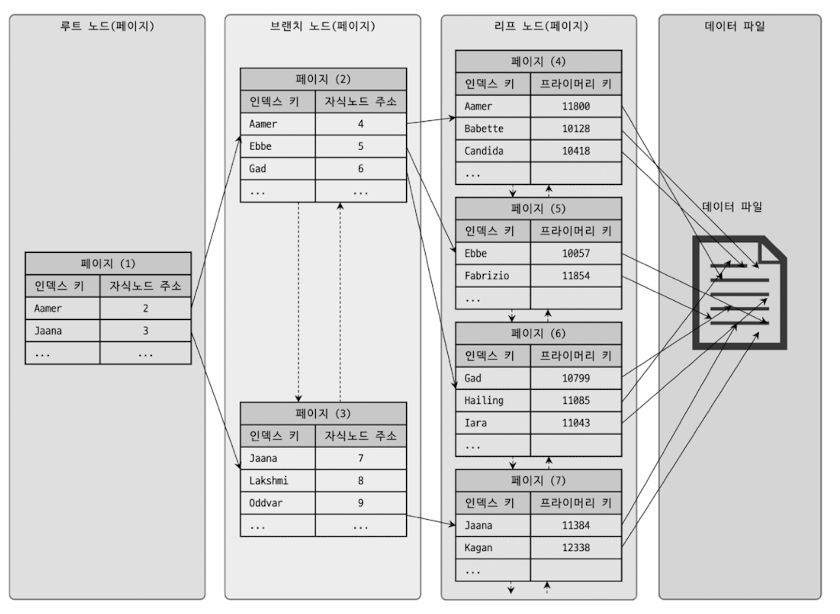
B-Tree 는 위 그림과 같이 최상위에 하나의 루트 노드(Root node) 가 존재하고 그 아래 자식 노드가 존재합니다.
그리고 트리의 최하단에 있는 리프 노드(Leaf node) 는 항상 데이터 레코드의 주소값을 갖습니다.
이 인덱스를 활용하는 방식은 스토리지 엔진마다 다른데요.
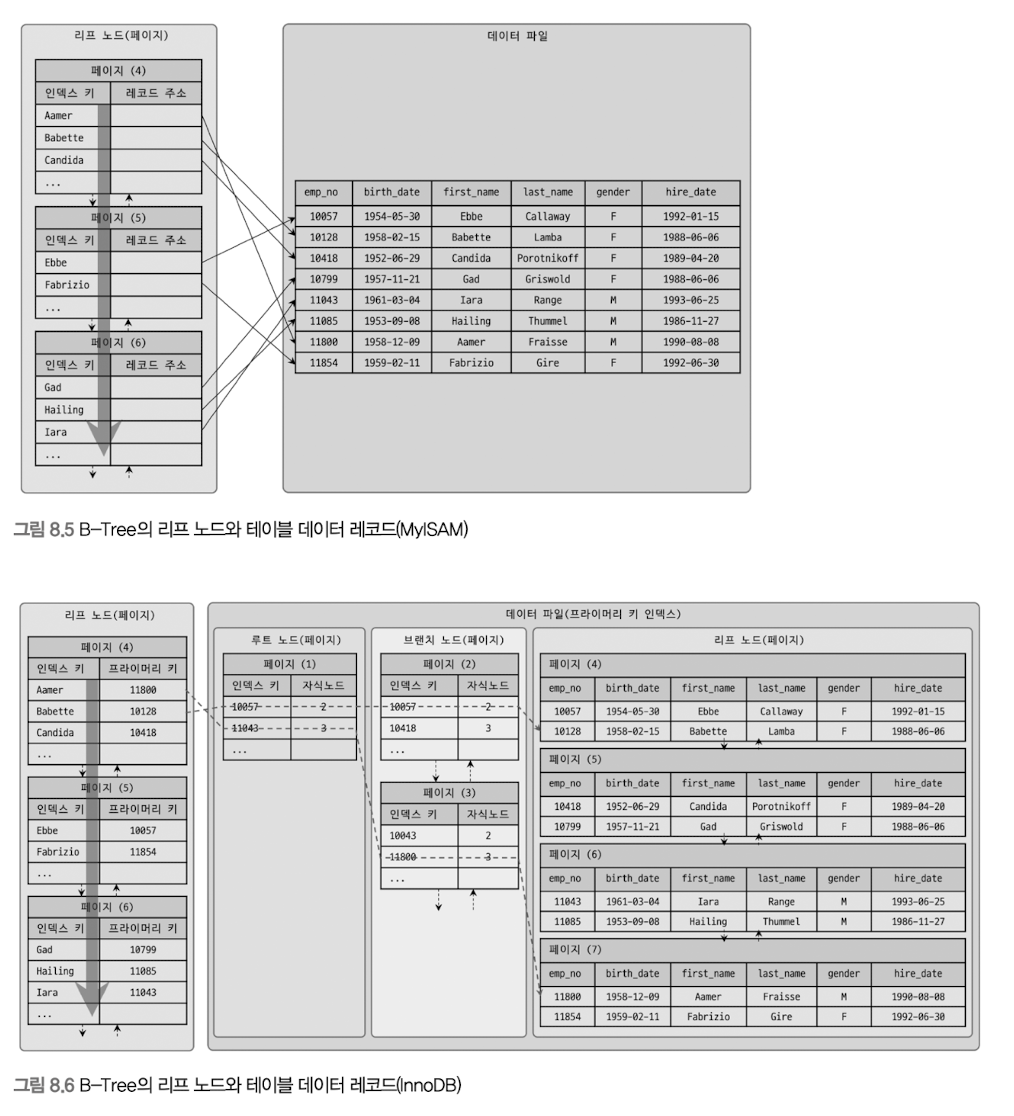
리프 노드에서 바로 레코드를 참조하는 MyISAM 과는 다르게, InnoDB 는 PK 를 참조한다는 것을 알 수 있습니다.
이는 InnoDB 가 기본적으로 클러스터드 인덱스(Clustered Index)를 적용하기 때문입니다.
보기에는 한번 더 트리를 타야하는 InnoDB 의 인덱스 구조가 비효율적일 것 같지만, 각각 장단점이 있다고 하는데요.
이는 나중에 자세하게 다뤄 볼 예정입니다.
3-2. B-Tree 인덱스 키 추가 및 삭제
테이블의 레코드에 변화가 생기면, 인덱스에도 변화가 발생합니다.
이 변화가 어떻게 일어나는지 이해하면, 쿼리 성능을 쉽게 예측할 수 있습니다.
3-2-1. 인덱스 키 추가
새로운 키 값이 B-Tree 에 저장될 때, 적절한 노드를 찾아 리프 노드에 저장합니다.
그런데 리프 노드가 꽐 찰 경우에는, Split 이 일어나는데요.
꽉 찬 노드를 절반으로 나눠서 2개의 리프 노드로 나누게 됩니다.
그래서 B-Tree 는 상대적으로 쓰기 작업(새로운 키 추가) 에 비용이 많이 든다고 할 수 있습니다.
3-2-2. 인덱스 키 삭제
삭제 작업은, 해당 리프 노드를 삭제 마크만 하면 작업이 완료됩니다.
이렇게 마스킹된 공간은 그대로 방치하거나 재활용할 수 있다고 합니다.
하지만 이 역시 디스크 I/O 가 발생하기 때문에 MySQL 5.5 이상의 InnoDB 에서는 버퍼링 처리가 될 수 있다고 합니다.
(참고로, 체인지 버퍼가 없는 MEMORY 나 MyISAM 은 바로 삭제처리됨)
3-2-3. 인덱스 키 변경
B-Tree 는 값에 따라 정렬된 형태이기 때문에, 단순히 해당 인덱스의 값만 변경할 수는 없습니다.
그래서 기존 키 값을 삭제한 후, 새로 추가하는 형태로 처리 됩니다.
3-2-4. 인덱스 키 검색
앞서 알아본 것 처럼, 인덱스는 INSERT, UPDATE, DELETE 작업 모두에 오버헤드가 생깁니다.
그럼에도 인덱스를 사용하는 이유는 빠른 검색(SELECT) 때문입니다.
빠른 검색이 가능한 이유는 무작정 찾는것 아닌, 효율적인 트리 탐색(Tree search) 과정 때문인데요.
이는 100% 일치하는 데이터를 검색하는 경우에 효율적으로 활용된다고 합니다.
사실 이 부분은 UPDATE, DELETE 의 WHERE 조건에서 특정 레코드를 찾을때도 사용된다고 하니
UPDATE, DELETE 입장에서도 마냥 손해보는것 만은 아닙니다.
3-3. B-Tree 인덱스 사용에 영향을 미치는 요소
B-Tree 인덱스는 칼럼의 크기, 레코드 수, 유니크 키 개수 에 의해 영향을 받습니다.
3-3-1. 인덱스 키 값의 크기
InnoDB 가 디스크에 데이터를 저장하는 기본 단위는 페이지(Page) 또는 블록(Block) 이라고 합니다.
또한 InnoDB 내부의 버퍼 풀에서 데이터를 버퍼링 하는 기본 단위이기도 합니다.
이 페이지의 기본 크기는 16KB 이지만 innodb_page_size 시스템 변수로 4KB~64KB 사이의 값을 선택할 수 있습니다.
인덱스를 생성하면 이 페이지에 인덱스 키 가 저장되는데요
그러면 당연히 인덱스 키 의 크기에 따라 한 페이지에 저장할 수 있는 개수가 정해지게 됩니다.
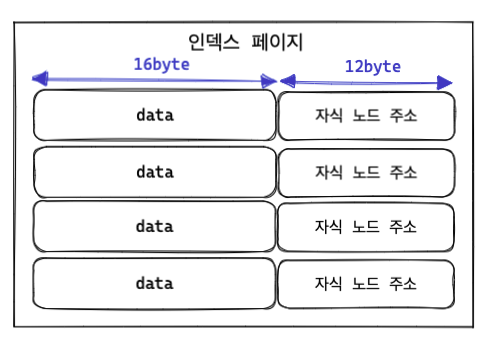
위 그림은 크기가 16byte 인 컬럼에 대해 성성된 인덱스의 예시입니다.
이 예시에 따르면, 인덱스 키 하나의 크기는 (16 + 12)byte 가 됩니다.
그래서 한 페이지에 저장할 수 있는 키의 개수는 16 * 1024 / (16 + 12) = 약 585 라고 계산됩니다.
하지만, 컬럼의 크기가 2배로 늘어나면 어떨까요?
그러면 16 * 1024 / (32 + 12) = 약 372 입니다.
이때 500개의 키에 대한 조회 요청이 들어오면 컬럼 크기가 16byte 인 경우에는 한 페이지에서 모두 조회할 수 있지만,
컬럼 크기가 32byte 인 경우에는 2개의 페이지에서 조회해야합니다.
즉, 컬럼의 크기가 클수록 인덱스 탐색에도 더 많은 오버헤드가 발생한다는 의미입니다.
3-3-2. B-Tree 깊이
위에서 인덱스 키의 크기에 따라, 한 페이지에 얼마만큼의 인덱스 키가 저장될 수 있는지 알아봤습니다.
컬럼의 크기가 16byte 인 경우에는 한 페이지당 585개, 32byte 인 경우에는 372개를 저장할 수 있었는데요.
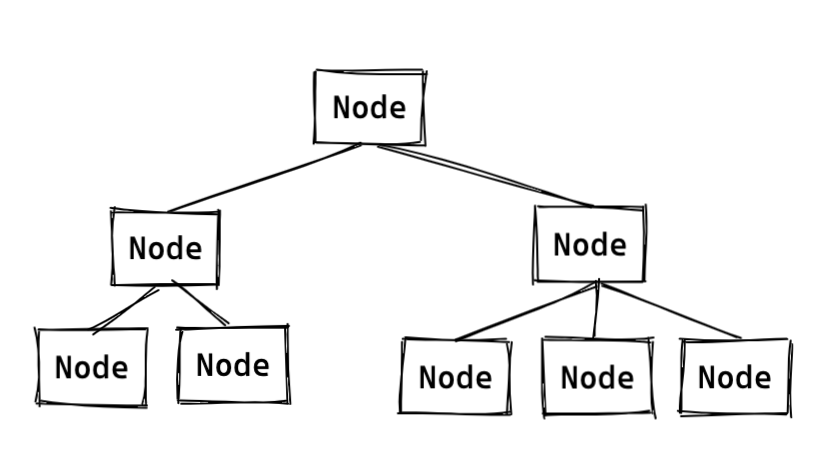
이전에 알아본 것 처럼 B-Tree 는 루트 노드, 브랜치 노드, 리프 노드 등으로 구성되어있습니다.
그러면 이번에는 깊이(Depth)가 3인 B-Tree 에서 몇개의 키 값을 가질 수 있는지 비교해보겠습니다.
먼저 컬럼이 16byte 인 경우 585^3 = 200,201,625 로 약 2억개의 키를 저장할 수 있습니다.
그리고 컬럼이 32byte 인 경우는 372^3 = 51,478,848 로 약 5천만개의 키를 저장할 수 있습니다.
데이터 컬럼의 크기는 2배로 늘었지만, 저장 가능한 키의 개수는 1/4로 줄어들었습니다.
이를 보면, B-Tree 에서 저장할 수 있는 키의 개수도 컬럼의 크기에 영향을 받는다는 것을 알 수 있습니다.
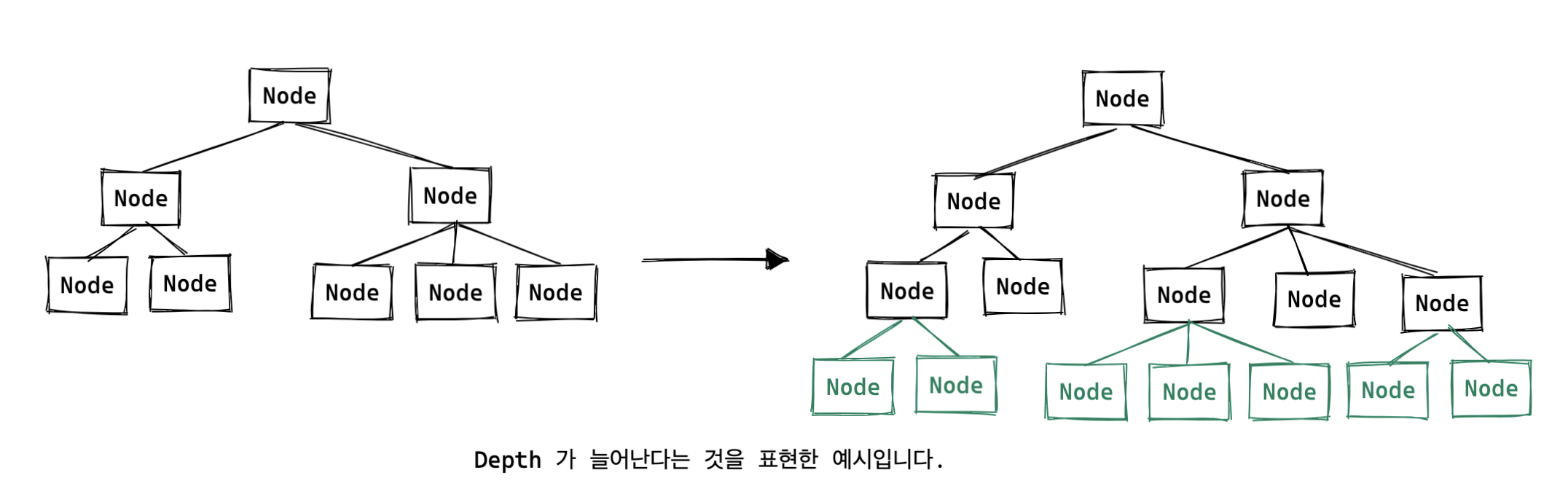
만약 깊이가 저장할 수 있는 키의 개수를 넘어선다면, 내부적으로 B-Tree 의 Depth 를 한 단계 늘리는 작업을 합니다.
깊이가 3인 B-Tree 였다면 4로, 4였다면 5로 늘어나게 됩니다.
3-3-3. 선택도(기수성)
인덱스에서 선택도(Selectivity) 또는 기수성(Cardinality)은 모든 인덱스키 값 가운데 유니크한 값의 수를 의미합니다.
100개의 값 중에서 유니크한 값의 개수가 30개라면, 기수성은 30입니다.
기수성이 낮으면 중복된 값이 많다는 것이니 검색할 대상이 많아져서 인덱스 키의 선택도가 낮아집니다.
반면에 기수성이 높으면(중복된 값이 적으면) 검색할 대상이 줄어들어서 키의 선택도가 높아져서 빠르게 처리됩니다.
물론 인덱스는 단순히 탐색뿐만 아니라, 정렬, 그루핑과 같은 작업의 속도도 올릴 수 있기 때문에,
상황에 맞게 적절하게 사용하는것이 중요합니다.
10,000개의 컬럼이 있는 tbl 이라는 테이블이 있습니다.
이 테이블에는 country 라는 컬럼이 있고, INDEX 가 걸려있습니다.
> SELECT * FROM tbl
WHERE country='KOREA' AND city='BUSAN';위 쿼리가 실행될 때, 다음 두 시나리오에 대해 어떻게 처리되는지 생각해보겠습니다.
- country 의 기수성이 10 인 경우
중복되지 않은 값이 10개 라는 의미이고, country 에 의해 약 10,000/10 개의 레코드가 걸러집니다.
걸러진 1,000개의 레코드 중에서 city 가 'BUSAN' 인 항목을 찾는데요.
'BUSAN' 인 레코드가 1건이라면, 나머지 999건은 불필요하게 탐색한 레코드가 됩니다. - country 의 기수성이 1000 인 경우
중복되지 않은 값이 1000개 라는 의미이고, country 에 의해 약 10,000/1,000 개의 레코드가 걸러집니다.
걸러진 10개의 레코드 중에서 city 가 'BUSAN' 인 항목을 찾는데요.
'BUSAN' 인 레코드가 1건이라면, 나머지 9건만 불필요하게 탐색한 레코드가 됩니다.
이 처럼 유니크한 값의 개수(기수성)은 쿼리의 효율성에 큰 영향을 미친다는것을 알 수 있습니다.